Why randomized controlled trials matter and the procedures that strengthen them
Randomized controlled trials are a key tool to study cause and effect. Why do they matter and how do they work?
At Our World in Data, we bring attention to the world's largest problems. We explore what these problems are, why they matter and how large they are. Whenever possible, we try to explain why these problems exist, and how we might solve them.
To make progress, we need to be able to identify real solutions and evaluate them carefully. But doing this well is not simple. It's difficult for scientists to collect good evidence on the costs and benefits of a new idea, policy, or treatment. And it's challenging for decision-makers to scrutinize the evidence that exists, to make better decisions.
What we need are reliable ways to distinguish between ideas that work and those that don't.
In this post, I will explain a crucial tool that helps us do this – randomized controlled trials (RCTs). We will see that RCTs matter for three reasons: when we don't know about the effects of interventions, when we don't know how to study them, and when scientific research is affected by biases.
What are randomized controlled trials?
To begin with, what are RCTs? These are experiments where people are given, at random, either an intervention (such as a drug) or a control and then followed up to see how they fare on various outcomes.
RCTs are conducted by researchers around the world. In the map, you can see how many RCTs have ever been published in high-ranked medical journals, by the country where the first author was based. Over 18,000 of these were from the United States, but most countries have had fewer than a hundred.1 RCTs have also become more common over time.2
It's easy to take RCTs for granted, but these trials have transformed our understanding of cause and effect. They are a powerful tool to illuminate what is unknown or uncertain; to discern whether something works and how well it works.
But it's also important to recognize that these trials are not always perfect, and understand why.
The strengths of RCTs are subtle: they are powerful because of the set of procedures that they are expected to follow. This includes the use of controls, placebos, experimentation, randomization, concealment, blinding, intention-to-treat analysis, and pre-registration.
In this post, we will explore why these procedures matter – how each one adds a layer of protection against complications that scientists face when they do research.

The fundamental problem of causal inference
We make decisions based on our understanding of how things work – we try to predict the consequences of our actions.
But understanding cause and effect is not just crucial for personal decisions: our knowledge of what works can have large consequences for people around us.
An example is antiretroviral therapy (ART), which is used to treat HIV/AIDS. The benefits of these drugs were surprising. One of the first ART drugs discovered was azidothymidine, which had previously been abandoned as an ineffective treatment for cancer.3 The discovery that azidothymidine and other antiretroviral therapies worked, and their use worldwide, has prevented millions of deaths from HIV/AIDS, as the chart shows.

Discovering what works can save lives. But discovering what doesn’t work can do the same. It means we can redirect our time and resources away from things that don't work, towards things that do.
Even when we already know that something works, understanding how well it works can help us make better decisions.
An example for this is the BCG vaccine, which reduces the risk of tuberculosis. The efficacy of this vaccine is different for different people around the world, and the reasons for this are unclear.4 Still, knowing this is informative, because it tells us that more effort is needed to protect people against the disease in places where the benefit of the vaccine is low.
If there was a reliable way to know about the effects of the measures we took, we could prioritize solutions that are most effective.
So, how would we understand cause and effect without trials?
One way is through observation: we can observe what different people did and track their outcomes afterwards. But it's possible that the events that followed their actions were simply a coincidence, or that they would have happened anyway.
The biggest challenge in trying to understand causes and effects is that we are only able to see one version of history.
When someone makes a particular decision, we are able to see what follows, but we cannot see what would have happened if they had made a different decision. This is known as “the fundamental problem of causal inference."5
What this means is that it is impossible to predict the effects that an action will have for an individual person, but we can try to predict the effects it would have on average.
Why randomized controlled trials matter
Sometimes we do not need an RCT to identify causes and effects. The effect of smoking on lung cancer is one example, where scientists could be confident as early as the 1960s that the large increase in lung cancer rates could not have been caused by other factors.
This was because there was already knowledge from many different lines of evidence.6 Experiments, biopsies and population studies all showed that cigarette smoke was associated with specific changes in lung tissue and with the incidence of lung cancer. The association was so large and consistent that it could not be explained by other factors.7
Even now, smoking is estimated to cause a large proportion of cancer deaths in many countries, as you can see in the chart.
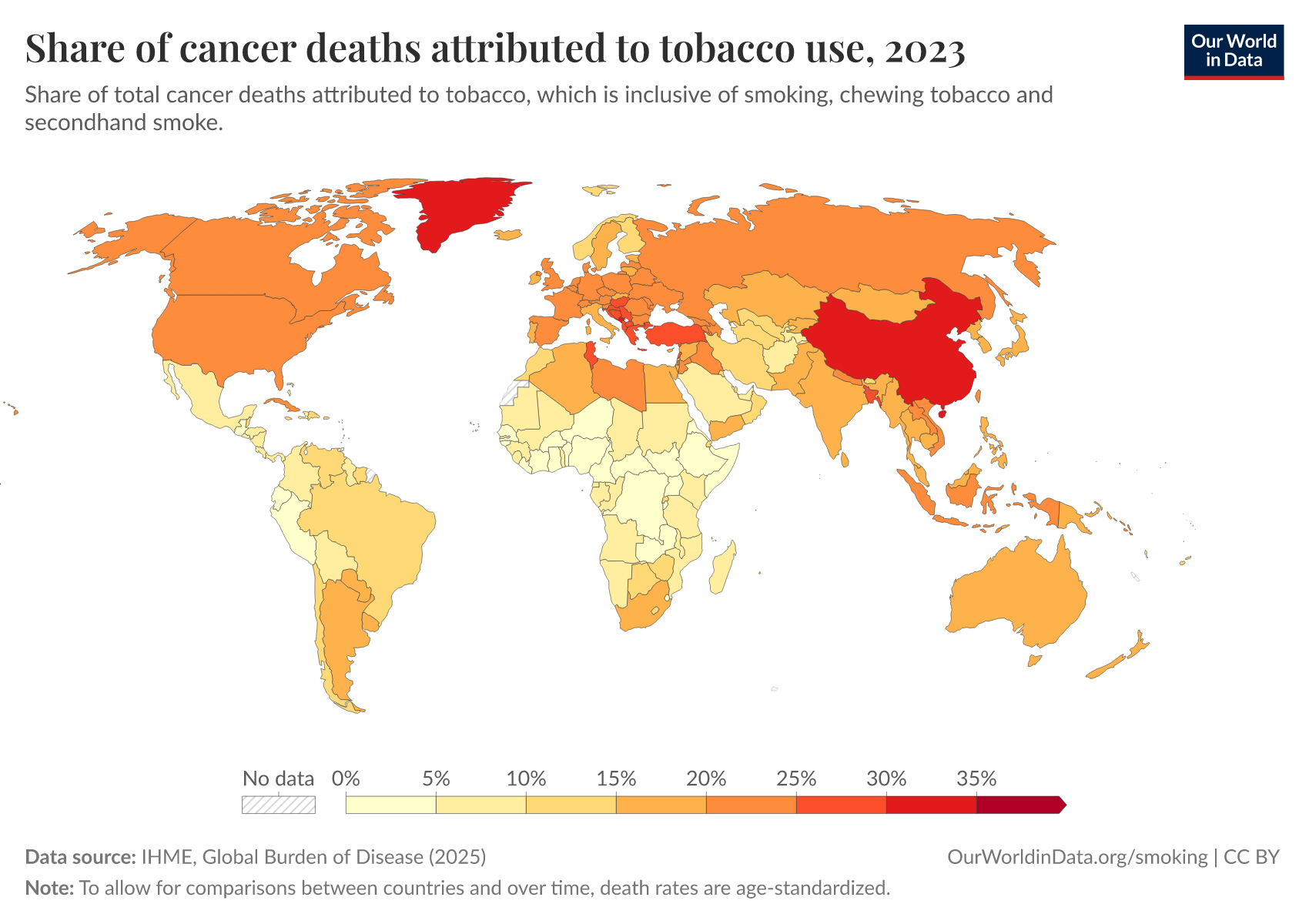
But in other situations, RCTs have made a huge difference to our understanding of the world. Prioritizing the drugs that were shown to be effective in trials saved lives, as we saw with the example of antiretroviral therapy to treat HIV/AIDS.
People sometimes refer to RCTs as the "gold standard of evidence", but it's more useful to recognize that their strengths emerge from a set of procedures that they aim to follow.
Why do RCTs matter?
In my opinion, even though we do have lots of knowledge about various topics, these trials matter for three reasons. They matter because we may not know enough, because we can be wrong, and because we might see what we want to see.
First, they matter when we don't know.
Randomized controlled trials can illuminate our understanding of effects, especially when there is uncertainty around them. They can help resolve disagreements between experts.
In some cases, scientists can use other methods to investigate these topics. But when there is insufficient knowledge, other methods may not be enough.
This is because, in a typical study, scientists need to be able to account for the possibility that other factors are causing the outcome.
They need to have knowledge about why an effect usually occurs and whether it will happen anyway. They need to know about which other risk factors can cause the outcome and what makes it likely that someone will receive the treatment. They also need to know how to measure these factors properly, and how to account for them.
The second reason they matter is when we are wrong.
Even when scientists think they know which risk factors affect the outcome, they might be incorrect. They might not account for the right risk factors or they might account for the wrong ones.
In an RCT where scientists use randomization, blinding and concealment, they can minimize both of these problems. Despite people's risks before the trial, the reason that someone will receive the treatment is the random number they are given. The reason that participants in each group differ at the end of the study is the group they were randomized to.
Even if we don't know about other risk factors, or even if we are wrong about them, these procedures mean that we can still find out whether a treatment has an effect and how large the effect is.
The third reason is when we see what we want to see.
When participants expect to feel different after a treatment, they might report that they feel different, even if they didn't receive the treatment at all.
When scientists want to see people improve after a treatment, they might decide to allocate the treatment to healthier participants. They might measure their data differently or re-analyze their data until they can find an improvement. They might even decide against publishing their findings when they don't find a benefit.
If scientists use concealment, blinding, and pre-registration, they can reduce these biases. They can protect research against their own prejudices and the expectations of participants. They can also defend scientific knowledge from poor incentives, such as the desires of scientists to hype up their findings and the incentives for pharmaceutical companies to claim that their drugs work.
The layers of protection against bias
Previously, I described how the strengths of RCTs emerge from the set of procedures that they aim to follow.
In medicine, this commonly includes the use of controls, placebos, experimentation, randomization, concealment, blinding, intention-to-treat analysis, and pre-registration.8 Each of these helps to protect the evidence against distortions, which can come from many sources. But they are not always enforced. Below, we will explore them in more detail.
The control group gives us a comparison to see what would have happened otherwise
The most crucial element to understand causes and effects is a control group.
Let's use antidepressants as an example to see why we need them.
If no one in the world received antidepressants, we wouldn’t know what their effects were. But the opposite is also true. If everyone received antidepressants, we wouldn't know how things would be without them.
In order to understand the effect of an antidepressant, we need to see which other outcomes are possible. The most important thing we need to understand effects is a comparison – we need some people who receive the treatment and some who don’t. The people who don’t could be our control group.
An ideal control group should allow us to control the biases and measurement errors in a study completely.
For example, different doctors may diagnose depression differently. If someone had symptoms of depression, then the chances they get diagnosed should be equal in the antidepressant group and the control group. If they weren't equal, we could mistake differences between the groups for an effect of antidepressants, even if they didn't have any effect.
In fact, an ideal control group should allow us to control the total effects of all of the other factors that could affect people's mood, not just control for the biases and errors in studies.
As an example, we know that the symptoms of depression tend to change over time, as I explained in this earlier post.
You can see this in the chart. This shows that the symptoms of depression tend to decline over time, among people who are diagnosed with depression but not treated for it. This is measured by seeing how many patients would still meet the threshold for a diagnosis of depression later on.
Almost a quarter of patients with depression (23%) would no longer meet the threshold for depression after three months, despite receiving no treatment. Just over half (53%) would no longer meet the threshold after one year.9 This change is known as "regression to the mean."
If we didn’t have a control group in our study, we might misattribute such an improvement to the antidepressant. We need a control group to know how much their symptoms would improve anyway.
Placebos allow us to account for placebo effects
Some types of controls are special because they resemble the treatment without actually being it – these controls are called placebos. An ideal placebo has all the qualities above and also allows us to account for "placebo effects." In this case, the placebo effect refers to when people's moods improve from the mere procedure of receiving the antidepressant.
For example, taking a pill might improve people's mood because they believe that taking a pill will give them some benefit, even if the pill does not actually contain any active ingredient.
How large is the placebo effect?
Some clinical trials have tried to estimate this by comparing patients who received a placebo to patients who received no treatment at all. Overall, these studies have found that placebo effects are small in clinical trials for many conditions, but are larger for physical treatments, such as acupuncture to treat pain.10
Placebo effects tend to be larger when scientists are recording symptoms reported by patients, rather than when they are measuring something that can be verified by others, such as results from a blood test or death.
For depression, the placebo effect is non-significant. Studies do not detect a difference in the moods of patients who receive a placebo and those who do not receive any treatment at all.11 Instead, the placebo group serves as a typical control group, to show what would happen to these patients even if they did not receive treatment.
Randomization ensures that there are no differences between control and treatment group apart from whether they received the treatment
Before participants are enrolled in a trial, they might already have different levels of risk of developing the outcomes.
Let's look at an example to illustrate this point.
Statins are a type of drug commonly used to prevent stroke. But strokes are more common among people who use statins. Does that mean that statins caused an increase in the rates of stroke?
No – people who are prescribed statins are more likely to have cardiovascular problems to begin with, which increases the chances of having a stroke later on. When this is accounted for, researchers find that people who take statins are actually less likely to develop a stroke.12
If researchers simply compared the rates of stroke in those who used statins with those who did not, they would miss the fact that there were other differences between the two groups, which could have caused differences in their rates of stroke.
Important differences such as these – which affect people's likelihood of receiving the treatment (using statins) and also affect the outcome (the risk of a stroke) – are called ‘confounders’.
But it can be difficult to know what all of these confounders might be. It can also be difficult to measure and account for them properly. In fact, scientists can actually worsen a study by accounting for the wrong factors.13
What happens when participants are randomized in a trial?
Randomization is the procedure of allocating them into one of two groups at random.
With randomization, the problems above are minimized: everyone has the possibility of receiving the treatment. Whether people receive the treatment is not determined by the risks they have, but whether they are randomly selected to receive the treatment.
So, the overall risks of developing the outcome in one group become comparable to the risks in the other group.
Randomization means that it is not a problem when there are confounders that are not known or not measured. Researchers don't have to know about why or how the outcome usually occurs.14
Concealment and blinding limit the biases of researchers and expectations of participants
In a clinical trial, participants or scientists might realize which groups they are assigned to. For example, the drug might smell, taste or look different from the placebo. Or it might have obvious benefits or different side effects compared to the placebo.15
Concealment is a first step in preventing this: this is the procedure of preventing scientists from knowing which treatment people will be assigned to.
Blinding is a second step: this is the procedure of preventing participants and scientists from finding out which treatment group people have been assigned to.16
When blinding is incomplete, it can partly reverse the benefits of randomization. For example, in clinical trials for oral health, the benefits of treatments appear larger when patients and the scientists who assess their health are not blinded sufficiently.17
If randomization was maintained, the only reason that groups would differ on their outcomes was the treatment they received. However, if the treatments were not hidden from scientists and participants, other factors could cause differences between them.
Sometimes, blinding is not possible – there might not be something that is safe and closely resembles the treatment, which could be used as a placebo.
Fortunately, this does not necessarily mean that these trials cannot be useful. Researchers can measure verifiable outcomes (such as changes in blood levels or even deaths) to avoid some placebo effects.
But even when blinding occurs, participants and researchers might still make different decisions, because of the effects of the treatment or placebo.
For example, some participants might decide to withdraw from the trial or not follow the protocols of the trial closely. Similarly, scientists might guess which groups people are in and therefore treat them differently or measure their outcomes in a biased way.
It's difficult to predict how this might affect the results of a trial. It could cause us to overestimate or underestimate the benefit of a treatment. For example, in the clinical trials for Covid-19 vaccines, some participants may have guessed that they received the vaccine because they experienced side effects.
So, they may have believed that they were more protected and took fewer precautions. This means they may have increased their risk of catching Covid-19. This would make it appear as if the vaccines gave less protection than they actually did: it would result in an underestimate of their efficacy.
Preregistration allows us to hold researchers accountable to their original study plans
Some of the procedures we've explored so far are used to safeguard research against errors and biases that scientists can have. Pre-registration is another procedure that contributes to the same goal.
After the data in a study is analyzed, scientists have some choice in which results they present to their colleagues and the wider community. This opens up research to the possibility of cherry-picking.
This problem unfortunately often arises in studies that are sponsored by industry. If a pharmaceutical company is testing their new drugs in trials, disappointing results can lead to financial losses. So, they may decide not to publish them.
But this problem is not limited to trials conducted by pharmaceutical companies.
For many reasons, scientists may decide not to publish some of their studies. Or they might re-analyze their data in a different way to find more positive results. Even if scientists want to publish their findings, journals may decide not to publish them because they may be seen as disappointing, controversial or uninteresting.
To counter these incentives, scientists can follow the practice of "pre-registration." This is when they publicly declare which analyses they plan to do in advance of collecting the data.
In 2000, the United States Food and Drug Administration (FDA) established an online registry for the details of clinical trials. The FDA required that scientists who were studying therapies for serious diseases needed to provide some details of their study designs and the outcomes that they planned to investigate.18
This requirement reduced the bias towards positive findings in published research. We see evidence of this in the chart, showing clinical trials funded by the National Heart, Lung and Blood Institute (NHLBI), which adopted this requirement.
Before 2000 – when pre-registration of studies was not required – most candidate drugs to treat or prevent cardiovascular disease showed large benefits. But most trials published after 2000 showed no benefit.19
Over the last two decades, this practice was strengthened and expanded. In 2007, the FDA required that most approved trials must be registered when people are enrolled into the study. They introduced notices and civil penalties for not doing so. Now, similar requirements are in place in Europe, Canada and some other parts of the world.20
Importantly, sponsors of clinical trials are required to share the results online after the trial is completed.
But unfortunately many still violate these requirements. For example, less than half (40%) of trials that were conducted in the US since 2017 actually reported their results on time.21
Here, you can see patterns in reporting results in Europe. According to EU regulations, all clinical trials in the European Economic Area are required to report their results to the European Clinical Trials Register (EU-CTR) within a year of completing the trial. But reporting rates vary a lot by country. By January 2021, most clinical trials by non-commercial sponsors in the UK (94%) reported their results in time, while nearly none (4%) in France had.22
Although a large share of clinical trials fail to report their results when they are due, this has improved recently: only half (50%) of clinical trials by non-commercial sponsors reported their results in time in 2018, while more than two-thirds (69%) did in 2021.23
Pulling the layers together
Together, these procedures give us a far more reliable way to distinguish between what works and what doesn't – even when we don't know enough, when we're wrong and when we see what we want to see.
Unfortunately, we have seen that many clinical trials do not follow them. They tend not to report the details of their methods or test whether their participants were blinded to what they received. These standards cannot just be expected from scientists – they require cooperation from funders and journals, and they need to be actively enforced with penalties and incentives.
We've also seen that trials can still suffer from remaining problems: that participants may drop out of the study and not adhere to the treatment. And clinical trials tend to not share their data or the code that they used to analyze it.
So, despite all the benefits they provide, we shouldn't see these layers as a fixed checklist. Just as some of them were introduced recently, they may still evolve in the future – open data sharing, registered reports and procedures to reduce dropouts may be next on the list.24
The procedures used in these trials are not a silver bullet. But when they are upheld, they can make these trials a more powerful source of evidence for understanding cause and effect.
To make progress, we need to be able to understand the problems that affect us, their causes and solutions. Randomized controlled trials can give scientists a reliable way to collect evidence on these important questions, and give us the ability to make better decisions. At Our World in Data, this is why they matter most of all.
Acknowledgements
I would like to thank Darren Dahly, Nathaniel Bechhofer, Hannah Ritchie and Max Roser for reading drafts of this post and their very helpful guidance and suggestions to improve it.
Endnotes
Catalá-López, F., Aleixandre-Benavent, R., Caulley, L., Hutton, B., Tabarés-Seisdedos, R., Moher, D., & Alonso-Arroyo, A. (2020). Global mapping of randomised trials related articles published in high-impact-factor medical journals: a cross-sectional analysis. Trials, 21(1), 1-24.
Vinkers, C. H., Lamberink, H. J., Tijdink, J. K., Heus, P., Bouter, L., Glasziou, P., Moher, D., Damen, J. A., Hooft, L., & Otte, W. M. (2021). The methodological quality of 176,620 randomized controlled trials published between 1966 and 2018 reveals a positive trend but also an urgent need for improvement. PLOS Biology, 19(4), e3001162. https://doi.org/10.1371/journal.pbio.3001162
National Research Council (U.S.) (1993). The social impact of AIDS in the United States. 4. Clinical Research and Drug Regulation. National Academy Press.
Dockrell, H. M., & Smith, S. G. (2017). What Have We Learnt about BCG Vaccination in the Last 20 Years? Frontiers in Immunology, 8, 1134. https://doi.org/10.3389/fimmu.2017.01134
Mangtani, P., Abubakar, I., Ariti, C., Beynon, R., Pimpin, L., Fine, P. E. M., Rodrigues, L. C., Smith, P. G., Lipman, M., Whiting, P. F., & Sterne, J. A. (2014). Protection by BCG Vaccine Against Tuberculosis: A Systematic Review of Randomized Controlled Trials. Clinical Infectious Diseases, 58(4), 470–480. https://doi.org/10.1093/cid/cit790
Holland, P. W. (1986). Statistics and Causal Inference. Journal of the American Statistical Association, 81(396), 945–960. https://doi.org/10.1080/01621459.1986.10478354
Imbens, G. W., & Rubin, D. B. (2010). Rubin causal model. In Microeconometrics (pp. 229–241). Springer.
Rubin, D. B. (1977). Assignment to Treatment Group on the Basis of a Covariate. Journal of Educational Statistics, 2(1), 1–26. https://doi.org/10.3102/10769986002001001
Hill, G., Millar, W., & Connelly, J. (2003). “The Great Debate”: Smoking, Lung Cancer, and Cancer Epidemiology. Canadian Bulletin of Medical History, 20(2), 367-386.
Cornfield, J., Haenszel, W., Hammond, E. C., Lilienfeld, A. M., Shimkin, M. B., & Wynder, E. L. (1959). Smoking and Lung Cancer: Recent Evidence and a Discussion of Some Questions. JNCI: Journal of the National Cancer Institute. https://doi.org/10.1093/jnci/22.1.173
Although these procedures are also used outside of medicine, it can be difficult to apply them elsewhere. For example, in a trial that tests the effectiveness of talking therapy, it would be known to the participants that they are receiving it; it may not be possible to find a placebo control version to disguise the procedure. Due to constraints in length and focus, I will not detail the advantages of intention-to-treat analysis or experimentation.
Whiteford, H. A., Harris, M. G., McKeon, G., Baxter, A., Pennell, C., Barendregt, J. J., & Wang, J. (2013). Estimating remission from untreated major depression: A systematic review and meta-analysis. Psychological Medicine, 43(8), 1569–1585. https://doi.org/10.1017/S0033291712001717
Hróbjartsson, A., & Gøtzsche, P. C. (2010). Placebo interventions for all clinical conditions. Cochrane Database of Systematic Reviews. https://doi.org/10.1002/14651858.CD003974.pub3
Hróbjartsson, A., & Gøtzsche, P. C. (2001). Is the Placebo Powerless?: An Analysis of Clinical Trials Comparing Placebo with No Treatment. New England Journal of Medicine, 344(21), 1594–1602. https://doi.org/10.1056/NEJM200105243442106
Hróbjartsson, A., & Gøtzsche, P. C. (2010). Placebo interventions for all clinical conditions. Cochrane Database of Systematic Reviews. https://doi.org/10.1002/14651858.CD003974.pub3
Hróbjartsson, A., & Gøtzsche, P. C. (2001). Is the Placebo Powerless?: An Analysis of Clinical Trials Comparing Placebo with No Treatment. New England Journal of Medicine, 344(21), 1594–1602. https://doi.org/10.1056/NEJM200105243442106
Orkaby, A. R., Gaziano, J. M., Djousse, L., & Driver, J. A. (2017). Statins for Primary Prevention of Cardiovascular Events and Mortality in Older Men. Journal of the American Geriatrics Society, 65(11), 2362–2368. https://doi.org/10.1111/jgs.14993
Makihara, N., Kamouchi, M., Hata, J., Matsuo, R., Ago, T., Kuroda, J., Kuwashiro, T., Sugimori, H., & Kitazono, T. (2013). Statins and the risks of stroke recurrence and death after ischemic stroke: The Fukuoka Stroke Registry. Atherosclerosis, 231(2), 211–215. https://doi.org/10.1016/j.atherosclerosis.2013.09.017
Ní Chróinín, D., Asplund, K., Åsberg, S., Callaly, E., Cuadrado-Godia, E., Díez-Tejedor, E., Di Napoli, M., Engelter, S. T., Furie, K. L., Giannopoulos, S., Gotto, A. M., Hannon, N., Jonsson, F., Kapral, M. K., Martí-Fàbregas, J., Martínez-Sánchez, P., Milionis, H. J., Montaner, J., Muscari, A., … Kelly, P. J. (2013). Statin Therapy and Outcome After Ischemic Stroke: Systematic Review and Meta-Analysis of Observational Studies and Randomized Trials. Stroke, 44(2), 448–456. https://doi.org/10.1161/STROKEAHA.112.668277
Cinelli, C., Forney, A., & Pearl, J. (2020). A crash course in good and bad controls. Available at SSRN, 3689437:http://dx.doi.org/10.2139/ssrn.3689437
Aronow, P., Robins, J. M., Saarinen, T., Sävje, F., & Sekhon, J. (2021). Nonparametric identification is not enough, but randomized controlled trials are. ArXiv Preprint ArXiv:2108.11342.
Higgins, J. P. T., Altman, D. G., Gotzsche, P. C., Juni, P., Moher, D., Oxman, A. D., Savovic, J., Schulz, K. F., Weeks, L., Sterne, J. A. C., Cochrane Bias Methods Group, & Cochrane Statistical Methods Group. (2011). The Cochrane Collaboration’s tool for assessing risk of bias in randomised trials. BMJ, 343(oct18 2), d5928–d5928. https://doi.org/10.1136/bmj.d5928
Schulz, K. F., Chalmers, I., & Altman, D. G. (2002). The Landscape and Lexicon of Blinding in Randomized Trials. Annals of Internal Medicine, 136(3), 254. https://doi.org/10.7326/0003-4819-136-3-200202050-00022
Saltaji, H. et al. Influence of blinding on treatment effect size estimate in randomized controlled trials of oral health interventions. BMC Med Res Methodol18, 42 (2018).
Dickersin, K., & Rennie, D. (2012). The evolution of trial registries and their use to assess the clinical trial enterprise. Jama, 307(17), 1861–1864.
Kaplan, R. M., & Irvin, V. L. (2015). Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time. PLOS ONE, 10(8), e0132382. https://doi.org/10.1371/journal.pone.0132382
Dickersin, K., & Rennie, D. (2012). The evolution of trial registries and their use to assess the clinical trial enterprise. Jama, 307(17), 1861–1864. https://doi.org/10.1001/jama.2012.4230
DeVito, N. J., & Goldacre, B. (2021). Evaluation of Compliance With Legal Requirements Under the FDA Amendments Act of 2007 for Timely Registration of Clinical Trials, Data Verification, Delayed Reporting, and Trial Document Submission. JAMA Internal Medicine, 181(8), 1128. https://doi.org/10.1001/jamainternmed.2021.2036
Note: Data is shown until January 2021 for trials. After the UK left the European Union in January 2021, clinical trials in the UK were then no longer required to report their results to the EU-CTR. Only data from trials by non-commercial sponsors is shown. This includes trials sponsored by institutions such as universities, hospitals, research foundations and so on.
Dal-Ré, R., Goldacre, B., Mahillo-Fernández, I., & DeVito, N. J. (2021). European non-commercial sponsors showed substantial variation in results reporting to the EU trial registry. Journal of Clinical Epidemiology, S0895435621003577. https://doi.org/10.1016/j.jclinepi.2021.11.005
Dal-Ré, R., Goldacre, B., Mahillo-Fernández, I., & DeVito, N. J. (2021). European non-commercial sponsors showed substantial variation in results reporting to the EU trial registry. Journal of Clinical Epidemiology, S0895435621003577. https://doi.org/10.1016/j.jclinepi.2021.11.005
Chambers, C., & Tzavella, L. (2020). The past, present, and future of Registered Reports.
Wendler, D. The Ethics of Clinical Research. in The Stanford Encyclopedia of Philosophy (ed. Zalta, E. N.) (Metaphysics Research Lab, Stanford University, 2021).
London, A. J. Equipoise in Research: Integrating Ethics and Science in Human Research. JAMA 317, 525 (2017).
Cite this work
Our articles and data visualizations rely on work from many different people and organizations. When citing this article, please also cite the underlying data sources. This article can be cited as:
Saloni Dattani (2022) - “Why randomized controlled trials matter and the procedures that strengthen them” Published online at OurWorldinData.org. Retrieved from: 'https://archive.ourworldindata.org/20260710-182139/randomized-controlled-trials.html' [Online Resource] (archived on July 10, 2026).BibTeX citation
@article{owid-randomized-controlled-trials,
author = {Saloni Dattani},
title = {Why randomized controlled trials matter and the procedures that strengthen them},
journal = {Our World in Data},
year = {2022},
note = {https://archive.ourworldindata.org/20260710-182139/randomized-controlled-trials.html}
}Reuse this work freely
All visualizations, data, and articles produced by Our World in Data are completely open access under the Creative Commons BY license. You have the permission to use, distribute, and reproduce these in any medium, provided the source and authors are credited.
The data produced by third parties and made available by Our World in Data is subject to the license terms from the original third-party authors. We will always indicate the original source of the data in our documentation, so you should always check the license of any such third-party data before use and redistribution.
All of our charts can be embedded in any site.